3.1. Les transcriptions
Si transcrire, c’est trahir, en ce sens que le chercheur impose toujours déjà une interprétation aux données brutes qu’il traduit (Ochs, 1979), l’on pourrait voir dans une transcription minimale le moyen de limiter la part de ces impondérables. Pourtant, la sélection ainsi opérée est un choix qui engage bien plus encore que la tentative, quoique toujours imparfaite, de tout transcrire. En effet, sur quels critères privilégiera-t-on un niveau (le verbal, par exemple) au détriment d’un autre ? Il est évident que la sélection n’est jamais neutre ; et les conventions du format CHAT (Codes for the Human Analysis of Transcripts : MacWhinney, 2000) offrent aux chercheurs un inventaire varié de possibilités. Lorsque l’on travaille individuellement sur des données, on peut faire des choix raisonnés en se contentant des outils existants, ou en créant des conventions ad hoc. Il n’en va pas de même lorsqu’un groupe de chercheurs aux intérêts et compétences divers travaille ensemble sur les mêmes données. C’est ainsi que nous avons fait l’expérience, dans le cadre du projet Léonard 24 , de la mise en place d’un format de transcription enrichi permettant de condenser dans le « texte » le maximum d’informations tout en réduisant la part des choix, toujours subjectifs (Snyder, 2007). Ces enrichissements nous ont guidée dans l’analyse des données de Lyon et de Providence, où nous avons préalablement ajouté des annotations, concernant par exemple le mimo-gestuel.
La question se pose certes de savoir si l’on peut travailler sur le mimo-gestuel comme on travaille sur le langage, et examiner conjointement le développement de l’un et de l’autre ? Pour Teubert (2005), la linguistique de corpus ne peut pas s’attacher au non verbal, puisqu’on ne peut en donner d’interprétation sûre et fiable, de paraphrase semblable à celle qu’un linguiste est à même de proposer pour le langage écrit comme oral. Cette affirmation polémique a le mérite de montrer la difficulté de travailler sur deux media différents, et la nécessité de mener une réflexion préalable sur le bon usage d’outils avant tout conçus pour l’examen du langage oral. Lorsqu’on regarde une transcription au format CHAT (cf. infra, figure 13) les lignes dépendantes généralement utilisées à cette fin (qui apparaissent au-dessous des lignes de transcription orthographique et phonétique) montrent bien que transcrire le mimo-gestuel, comme les actions et les situations, revient à décrire et non pas à interpréter ou à spéculer sur des intentions des locuteurs en présence. À cela s’ajoute une particularité forte du type de discours et d’interaction étudiés en acquisition du langage : il est fréquent que les productions langagières et/ou gestuelles ne soient pas univoques, et varient fortement en fonction du contexte : ainsi des onomatopées comme poum, hop, etc., à propos desquelles il importe de savoir si elles ont été prononcées en tapant dans une balle ou en sautant, par exemple.
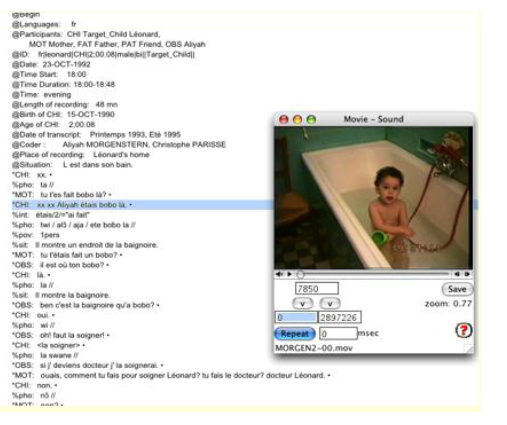
Pour cette étude, comme pour l’ensemble des analyses que nous présenterons, nous avons travaillé sur des transcriptions enrichies, ce qui suppose (en tout cas lorsque l’on ne fait pas soi-même la transcription, comme c’est le cas ici) que l’on effectue un premier visionnage des enregistrements en lisant la transcription à mesure, et qu’on y ajoute, sur des lignes dépendantes dédiées, des informations contextuelles et situationnelles, mais aussi des informations sur le posturo-mimo-gestuel.